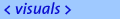

| Real-time 3D Video |
Differential StreamingOur concept of 3D video fragments exploits the spatio-temporal interframe coherence of multiple input streams by using a differential update scheme for dynamic point samples. The basic primitives of this scheme are the 3D video fragments, point samples with different attributes like, e.g., a position, a surface normal vector, and a color. The update scheme is expressed in terms of 3D fragment operators. We distinguish between three different types of operators:
The time sequence of these operators creates a differential fragment operator stream that updates a 3D video data structure on a remote site. An Insert operator results from the reprojection of a pixel with color attributes from image space back into three-dimensional object space. Any real time 3D reconstruction method which extracts depth and normals from images can be employed for this purpose. Note that the point primitives feature a one-to-one mapping between depth and color/texture samples. The 3D operators and associated data can be summarized as follows:
where p are the coordinates of a pixel, c its color, P the respective 3D coordinates of the point sample, and n its surface normal. Operation ModesThe popular MPEG video compression standard defines three different types of video frames: I-frames are coded without any references from past frames, they are self-contained; P-frames use motion-compensated prediction from the past I- or P-frame; B-frames use bidirectional prediction from the most recent and the closest future I- or P-frame. Note that the predicted P- and B-frames achieve the highest compression rates, but a sequence encoded exclusively with prediction frames can only be rendered correctly if the receiver retains the complete data stream. Problems may occur in many situations, e.g. parts of the data stream are lost during network transmission or the sender and the receiver are started asynchronously. Moreover, prediction errors accumulate over time. In the following, we use the nomenclature from 2D video coding for describing three different modes of our 3D video pipeline. We distinguish between three different modes of our 3D video pipeline.
|