Space-Time Body Pose Estimation in Uncontrolled Environments
M. Germann, T. Popa, R. Ziegler, R. Keiser, M. GrossProceedings of 3DIMPVT (Hangzhou, China, May 16-19, 2011), pp. 244-251
Abstract
We propose a data-driven, multi-view body pose estimation algorithm for video. It can operate in uncontrolled environments with loosely calibrated and low resolution cameras and without restricting assumptions on the family of possible poses or motions. Our algorithm first estimates a rough pose estimation using a spatial and temporal silhouette based search in a database of known poses. The estimated pose is improved in a novel pose consistency step acting locally on single frames and globally over the entire sequence. Finally, the resulting pose estimation is refined in a spatial and temporal pose optimization consisting of novel constraints to obtain an accurate pose. Our method proved to perform well on low resolution video footage from real broadcast of soccer games.
Overview
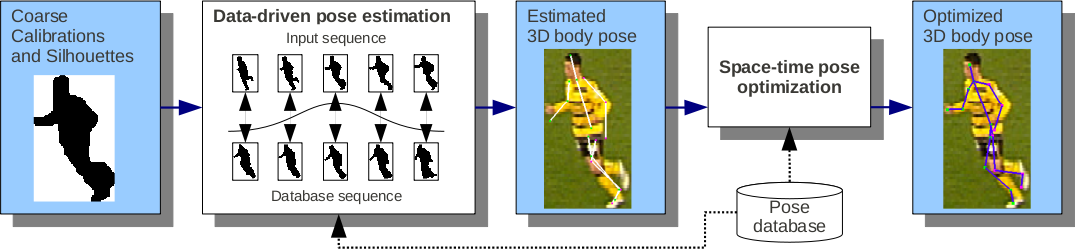
Our algorithm consists of two steps as illustrated in figure 2. In the first step, the algorithm extracts 2D poses for each individual camera view using a spatial-temporal silhouette matching technique, yielding a triangulated 3D pose guess. This pose detection is inherently prone to ambiguities, namely left right flips of symmetrical parts. Although the skeleton matches the silhouettes quite well, the arms or legs of the player can still be flipped. Due to occlusions and low resolution, these ambiguities are sometimes very difficult to spot even for the human eye. Therefore, we employ an optical flow based technique to detect the cases where flips occur, and correct them to obtain a consistent sequence. It is important to note that optical flow is in such setups not reliable enough for tracking the entire motion of a players body parts over an entire sequence, but it can be used for local comparisons as shown by Efros et al. [Efros03]. However, in general, no pose from the database will match the actual pose exactly. As a consequence, in the second part of the algorithm, this initial 3D pose is refined by an optimization procedure, which is based on spatio-temporal constraints. The resulting optimized 3D skeleton matches the silhouettes from all views and features temporal consistency over consecutive frames.



