| |
| |
| |
| |
| |
| |
| |
Data Struture
The data structure used to represent a model is described in the following diagram: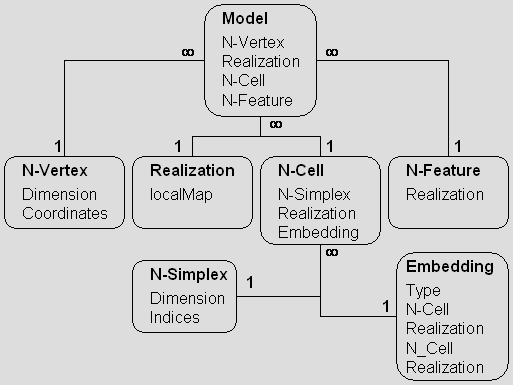
Assumptions on the input data
The goal of the NeMeSi framework is to represent a broad class of models, and to construct operators for them. The assumptions on the input data are as follows:- Models can be non-manifolds. An n-dimensional manifold surface has the property that the closed neighborhood of every point on the surface is homeomorphic to Rn. If this condition is not met, then the surface is a non-manifold.
- Models are represented as simplicial complexes, that is the intersection of two simplices is either empty or a simplex. An n-dimensional simplex is defined as the convex hull of n+1 affine independent vertices.
The representation
The goal of the data structure illustrated above is to model a large class of models efficiently. In particular, we want to be able to describe the semantic associated with a model. A model is described by:- A set of n-dimensional vertices. The position of each vertex in the model is stored only once, thus avoiding replication. This guarantees that any change of the geometric information on the model will not cause inconsistencies.
- A set of n-dimensional cells. An n-cell stores the topological information of part of the model. In particular, it stores a set of n-simplices and a set of embeddings, which describe how the cell is embedded in higher dimensional cells.
- A set of geometric realizations. A geometric realization defines an instance of an n-cell in space. This is implemented as a map, which maps the local indices of the simplices of a cell onto the global indices of the vertices of the model. This approach enables us to create cells that exists in more than a physical location, but that are really the same topological entity.
- A set of n-features. Features are used to store that information on the original surfaces used to construct a model. Without the use of features this information would be lost, since the boolean operation used in the construction process split surfaces into a collection of cells.
- A set of embeddings. An embedding describes how a realization of a lower dimensional
n-cell is embedded into a realization of a higher dimensional n-cell. We
us two types of embeddings:
- An l-seam connects the higher dimensional cells through the lower dimensional cell.
- An l-limit separates the higher dimensional cells by the lower dimensional cell.
Discussion
There are several advantages in using this representation, the most important of which is the ability to describe the semantics associated with a model. Consider the following example:



It should also be noted that by using the concept of disconnected components we were able to smooth across disconnected components of the model.