








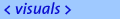

| Real-time 3D Video |
Dynamic System ControlMany real-time 3D video systems are employed for point-to-point communication. In such cases, the 3D video representation can be optimized for a single view point. Multi-point connections, however, require truly view-independent 3D video. In addition, 3D video systems can suffer from performance bottlenecks at all pipeline stages. Some performance issues can be locally solved, for instance by lowering the input resolution, or by utilizing hierarchical rendering. However, only the combined consideration of application, network and 3D video processing state leads to an effective handling of critical bandwidth and 3D processing bottlenecks. In the point-to-point setting the current virtual viewpoint allows one to optimize the 3D video computations by confining the set of relevant cameras. As a matter of fact, reducing the number of involved cameras or the resolution of the reconstructed 3D video object implicitly decreases the required networking bandwidth. Furthermore, the acquisition frame rate can be adapted dynamically. The aforementioned issues suggest a concept for dynamic system adaptation for the 3D video system. Active Camera ControlWe devise a concept for dynamic control of active cameras which allows for smooth transitions between subsets of reference cameras and efficiently reduces the number of involved cameras for 3D reconstruction. Furthermore, increasing the number of so-called texture active cameras enables a smooth transition from a view-dependent to a view-independent representation for 3D video. A texture active camera is a reference camera generating point samples. Each pixel classified as foreground in such a camera frame contributes color or texture samples to the set of 3D points in the 3D representation. Additionally, each camera might provide auxiliary information for the employed 3D reconstruction algorithm. We call the state of these cameras reconstruction active. Note that a camera can be both texture and reconstruction active. The state of a camera which does not provide data at all is called silent.
Illustration of the dynamic camera control. Green cameras are texture active, red cameras are reconstruction active, and yellow cameras are both texture and reconstruction active. Uncolored cameras are silent. Left: for one active camera. Right: for three active cameras. In order to select the k-closest cameras for the desired viewpoint as texture active cameras, we compare the angles between all camera look-at vectors and the desired viewing vector. Choosing the k-closest views minimizes artifacts arising from occlusions in the reference views. Experimentally, we found that for our target objects, i.e. humans, performs well. The selection of reconstruction active cameras has to be computed for all texture active cameras and is dependent on the employed 3D reconstruction method. Since our prototype system uses a shape-from-silhouette algorithm, each reconstruction active camera provides silhouette contours. Texture Activity LevelsA second strategy for dynamic system adaptation involves the number of reconstructed fragments. We define a texture activity level for each camera to determine the number of pixels fed into the 3D video pipeline. Initial levels for all texture active cameras are derived from the weight formulas for Unstructured Lumigraph Rendering. The texture activity level allows for smooth transitions between cameras and enforces epipole consistency. The resolution of the virtual view is also taken into account. In addition, texture activity levels are scaled with a system load penalty reflecting the reconstruction process. The penalty takes into account the load of the current frame and the activity levels of prior frames. If the load becomes too high, the texture activity level is reduced such that less pixels need to be processed. |


